- Published on
Build system modulaire avec Make
- Authors
- Name
Make est un outil formidable pour construire votre projet logiciel mais il est souvent difficile d'allier un système de construction simple et performant. Bien entendu, l'architecture présentée ici ne règlera pas tous les cas possibles mais a pour but d'apporter une solution pour des problématiques souvent recherchées.
Cahier des charges
Afin de bien délimiter les contours de notre build system, c'est-à-dire ce qu'il fait et ce qu'il ne fait pas, listons quelques propriétés fondamentales désirées.
Système modulaire
Votre projet aura tout intérêt à s'architecturer autour d'une organisation de code modulaire, ou par composants. Chaque fonction est ainsi bien détourée, indépendante et accessible via des interfaces agnostiques. Il y a plusieurs avantages à cela :
- Vos composants seront réutilisables
- Les changements seront moins lourds et potentiellement moins invasifs (pas de code spaghettis)
- Il est plus facile de tester un module indépendant, surtout avec des outils automatisés
Bien entendu cela est de la théorie, en pratique certains composants sont très fortement liés entre eux et il est facile, au cours d'un gros développement, de "casser" cette belle architecture. Il faudra donc prévoir beaucoup de tests et de revue de code pour éviter cet écueil.
Notre architecture logicielle par composant se matérialisera par un répertoire pour chaque module logiciel. Ce répertoire doit pouvoir être délocalisable, c'est-à-dire qu'il doit pouvoir se trouver à n'importe quel endroit d'une arborescence sans le modifier, notamment les chemins où se trouvent les fichiers sources.
Multi-cibles
Un projet logiciel aura très souvent besoin de générer plusieurs fichiers de sorties à partir d'un même ensemble de code source. Dans le développement sur cible embarqué par exemple (langage C/C++), on trouve ainsi :
- Un ou plusieurs exécutables (l'application)
- Un bootloader
- Un exécutable d'usine (tests, injection de clés de sécurité ou de paramètres spécifiques)
- Un exécutable pour les tests automatisés (Jenkins ...)
- Un exécutable de simulation (BSP simulée ou fonctionnant sur ordinateur hôte)
Dès lors, vu que les cibles vont partager beaucoup de code en commun, il faudra un système de construction lui aussi modulaire capable de récupérer différents modules logiciels pour une cible donnée.
Outils et systèmes variés
Lors d'un développement de logiciel embarqué, on va utiliser un compilateur dit croisé, c'est-à-dire qu'il fonctionne sur un ordinateur hôte pour une cible matérielle différente. Exemple: on construit sur Linux (x86_64) un programme pour Arduino (AVR 8 bits).
Or, il est souvent rusé de pouvoir faire fonctionner ce code embarqué sur cible PC, avec les interfaces matérielles simulées qui vont bien. L'avantage est de tester un code dans un environnement complètement différent : compilateur, OS, matériel. Si votre BSP (Board Support Package) est bien détournée (indépendante et aux interfaces agnostiques), alors vous pouvez également tenter de construire votre application sur une autre microcontrôleur. Par exemple, si votre cible principale est du ARM Cortex-m3, le compilateur IAR et l'OS Segger, tentez de le faire fonctionner sur un PIC32 (MIPS) avec GCC et FreeRTOS...
Si cela fonctionne, alors vous avez parfaitement "wrappé" vos interfaces systèmes et votre code source a été bien nettoyé de warnings. En pratique cela demande vraiment beaucoup de temps et de maintenance, surtout que les compilateurs ont tous leur lot d'extension propriétaire (pragma ...) et un format de linkage différent.
Simple!
Enfin, et ce n'est pas un moindre argument, gardons un système de construction simple ! Les systèmes à base de Makefile peuvent finir en véritable monstre impossible à maintenir. Pour y parvenir, ne tentons pas de résoudre tous les problèmes, surtout ceux liés à l'environnement du produit. S'il y a des spécificités, alors celles-ci seront gérées au niveau projet, pas au niveau du moteur.
Ajoutons des surcouches, et évitons d'ajouter des fonctions que très rarement utilisées qui n'apportent finalement pas grand chose. C'est là un bon exercice également, le développeur doit faire l'effort de distinguer, à tout moment :
- Si la fonction est générique, alors mettons la en standard, sous une forme agnostique (nommage, define ou option générique)
- Si la fonction est spécifique, la placer dans des fichiers propres au projet
Cela est valable pour les Makefile mais également pour le code source C. Le code spaghetti est généralement le résultat de cela : on retrouve de l'applicatif dans du protocole, du driver dans de l'applicatif... séparer, wrapper et interfacer, ça fonctionne !
Enfin, nous voulons également avoir une certaine simplicité dans l'écriture du makefile d'un module. Un seul fichier, simple à éditer pour ajouter des sources et c'est tout.
Architecture
Il existe deux grandes familles de moteur de construction basé sur Make :
- Les récursifs : Un makefile principal lance des sous makefile, un process est créé à chaque fois. Avantage: les sous modules peuvent être construits indépendamment, inconvénient: les variables ne peuvent pas être transmises du Makefile enfant au parent
- Les non-récursifs : le makefile principal inclue tous les sous makefile avant exécution
Nous allons nous orienter vers la deuxième famille de makefile, les non-récursifs. Ayant une petite expérience avec la première famille, il s'avère que les avantages sont peu nombreux par rapport à la complexité générale, un peu plus importante qu'avec les non-récursifs.
Organisation des répertoires
Voici ce que cela donne, en image :
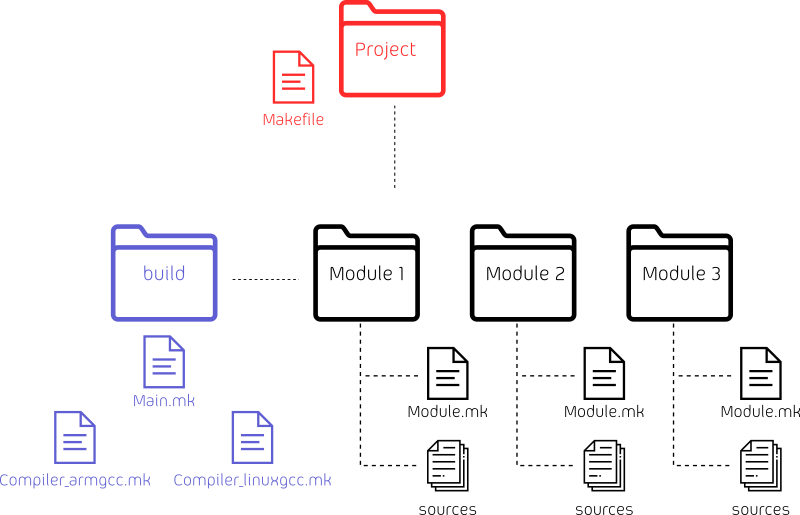
Chaque module, ou composant, est un répertoire. Celui-ci peut être organisé comme il veut à l'intérieur (avec des sous répertoires), même si le mieux est de respecter un certain standard au sein de votre projet (répertoire inc, src, doc etc.). A la racine de celui-ci se trouve notre fichier Makefile inclut par le moteur. Il ne se nomme pas "Makefile" pour ne pas confondre avec le fichier racine du projet, mais "Module.mk".
Le répertoire "build" à la racine du dépôt contient le build system proprement dit et sera l'emplacement des fichiers de sorties (objets, exécutables, map ...).
Le Makefile chapeau est donc situé à la racine. Il faut garder en tête certains standards et habitudes : quelqu'un ne connaissant pas votre architecture aura tendance à machinalement taper "make" tout court dans le répertoire de base pour construire la version "release". Il faut essayer de garder cette pratique même s'il est tout à fait valable et même conseillé d'ajouter d'autres cibles (make tests, make manuf, etc.).
Fichier module
Intéressons-nous au fichier make de chaque module. Comme on le souhaite, il se veut minimaliste afin de faciliter l'ajout de modules à un projet existant. La première chose à faire est de détecter dans quel chemin nous sommes. Pour cette fonctionnalité, nous avons piqué le code au projet Google Android qui a la même problématique que nous (en plus compliqué).
LOCAL_DIR = $(call my-dir)/
SOURCES += $(addprefix $(LOCAL_DIR),aes.c cipher.c cipher_wrap.c gcm.c)La deuxième ligne contient l'ajout des fichiers sources à la variable 'SOURCES'. Le moteur se chargera, en fonction de l'extension des fichiers, de les filtrer et d'appeler le bon programme pour les traiter (l'assembleur pour les .s, GCC pour les .c, G++ pour les .cpp par exemple).
Nous avons rempli notre cahier des charges au niveau de la simplicité, de la modularité et de la relocalisation des modules.
Si le module possède des sous répertoires, il suffit de les ajouter dans la variable 'INCLUDES' pour que les fichiers d'en-tête puissent être trouvés. Par défaut, le moteur ajoute chaque module d'un projet comme répertoire d'inclusion à la compilation ce qui permet d'utiliser des fichiers d'un autre module même si cela doit être utilisé avec parcimonie. En effet, il faut à tout pris casser le plus possible la dépendance entre les modules logiciels, sans ça il sera difficile de réutiliser un module sans ses petits copains.
Voici l'exemple avec des sous répertoires :
local_src= \
MyModule.cpp \
MyUtils.cpp \
ModuleMisc.cpp \
Yeah.cpp
LOCAL_DIR = $(call my-dir)/
INCLUDES += $(LOCAL_DIR)include
SOURCES += $(addprefix $(LOCAL_DIR)src/, $(local_src))Fichier projet
Le fichier projet se nomme "Makefile" et il est préférable de le placer à la racine du répertoire du projet pour le trouver rapidement. Nous allons uniquement regarder les parties intéressantes de ce fichier. Comme nous l'avons expliqué, ce fichier peut être vu comme le fichier principal de votre projet, celui qui va décrire les cibles à construire à l'aide des différents modules.
Une des premières choses à faire est de déclarer nos modules, ou ensemble de modules si besoin, en fonction de leur emplacement dans l'arborescence. Ici tous les chemins sont relatifs ce qui permet de garder une bonne clarté dans le fichier.
LIB_BASE := lib/system lib/database lib/application lib/crypto lib/ip
LIB_CLIENT := lib/serial lib/util
LIB_BSP := arch/hostExaminons maintenant comment nous allons construire une cible donnée, d'abord il faut la définir tous les modules qui la compose :
ifeq ($(MAKECMDGOALS), server)
APP_MODULES := src $(LIB_BASE) $(LIB_BSP) $(LIB_CLIENT)
APP_LIBPATH :=
APP_LIBS :=
endifIci nous utilisons la variable 'MAKECMDGOALS' de make qui nous indique quelle est la variable utilisée pour construire la cible et ainsi initialiser les variables du moteur de build aux bonnes valeurs. En effet, les variables 'APP_MODULES', 'APP_LIBPATH' et 'APP_LIBS' sont réservées au moteur.
Enfin, on inclue le moteur de build proprement dit, le fichier 'Main.mk', puis nous décrivons comment doit se construire la cible finale.
include build/Main.mk
server: $(OBJECTS)
$(call linker, $(OBJECTS), $(APP_LIBS), my_app_name)Notez que l'on peut spécifier le nom de l'exécutable final en variable d'appel de la fonction 'linker'. Le système est vraiment très simple d'écriture et permet de jouer avec les variables que vous voulez. Mais il n'est pas encore parfait !
Inconvénients
Dans le cadre d'un projet multi-cibles, il peut être intéressant de séparer le Makefile projet en deux sous fichiers. En effet dans l'exemple présenté ici on ne définit pas de cible par défaut, le 'make all'. Dans l'idée il s'agit de tout construire, toutes les cibles, alors qu'ici il faut explicitement écrire quelle cible unique nous voulons générer. Dès lors, le Makefile projet principal appellera un autre sous Makefile projet ou l'inclura selon l'astuce trouvée.
Notre moteur est également très lié à GCC, il faut donc que l'on définisse un système de variable d'architecture, passée en paramètre, et des fichiers de configuration dédiés à chaque compilateur (dans le monde embarqué il en existe plusieurs).
Enfin, on tentera de le faire évoluer pour intégrer Qt, un framework que j'utilise beaucoup mais un peu particulier à compiler.
Mais gardez à l'esprit qu'un moteur de construction, même s'il faut éviter de trop toucher ses entrailles une fois stable, est du aussi du code qu'il faudra maintenir et faire évoluer réguièrement à l'instar de tout autre code source.
Conclusion
Nous voici donc dotés d'un système simple, reproductible et extensible pour nos projets modulaires. Nous l'utiliserons dans le cadre d'un prochain petit projet mixant code embarqué et logiciel PC.